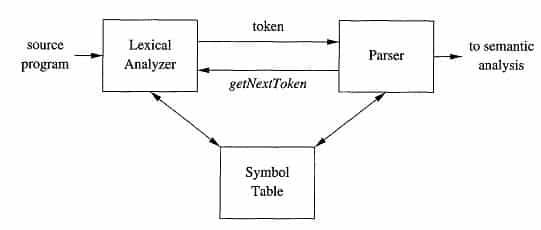
Lexical analyser – LEX
Lex stands for Lexical Analyzer. Lex is a tool for generating scanners. Scanners are programs that recognize lexical patterns in text. These lexical patterns (or regular expressions) are defined in a particular syntax. When Lex receives input in the form of a file or text, it attempts to match the text with the regular expression. It takes input one character at a time and continues until a pattern is matched. A matched regular expression may have an associated action. This action may also include returning a token. If, on the other hand, no regular expression can be matched, further processing stops and Lex displays an error message.The recognition of the expressions is performed by a deterministic finite automaton generated by Lex.The lexical analysis programs written with Lex chooses the longest match possible at each input point.
Lex and C are tightly coupled. A .l file (files in Lex have the extension .l) is passed through the lex utility, and produces output files in C(lex.yy.c). These file(s) are compiled to produce an executable version (a.out)of the lexical analyzer.
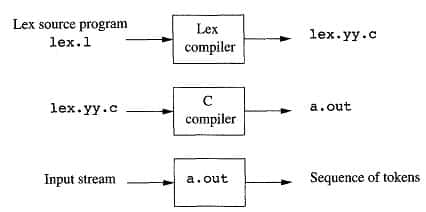
How to execute ?
Compile lex file using lex filename.l (to generate lex.yy.c)
Compile c file using cc lex.yy.c (to generate executable file a.out)
Execute the file using ./a.out
Regular expressions in Lex
Regular expressions in lex is a pattern description composed of metacharacters. Any regular expression may be expressed as a finite state automaton (FSA). Regular expressions are translated by lex to a computer program that mimics an FSA. Using the next input character and current state the next state is easily determined by indexing into a computer-generated state table. An expression is made up of symbols. Normal symbols are characters and numbers, but there are other symbols that have special meaning in Lex. Within a character class normal operators lose their meaning. If two patterns match the same string, the longest match wins. In case both matches are the same length, then the first pattern listed is used.Some of the symbols used in Lex are given below:
Character : Meaning
A-Z, 0-9, a-z (Characters and numbers that form part of the pattern.)
. ( Matches any character except \n)
– (Used to denote range. Example: A-Z implies all characters from A to Z.)
* (Match zero or more occurrences of the preceding pattern.)
+ (Matches one or more occurrences of the preceding pattern.)
? (Matches zero or one occurrences of the preceding pattern.)
$ (Matches end of line as the last character of the pattern.)
\ (Used to escape meta characters. Also used to remove the special meaning of characters)
^ (Negation.)
| (Logical OR between expressions.)
“” (Literal meanings of characters. Meta characters hold.)
( ) (Groups a series of regular expressions.)
[ ] (A character class. Matches any character in the brackets. If the first character is ^ then it indicates a negation pattern. Example: [abC] matches either of a, b, and C. )
{ } (Indicates how many times a pattern can be present. Example: A{1,3} implies one or three occurrences of A may be present.)
/ (Look ahead. Matches the preceding pattern only if followed by the succeeding expression. Example: A0/1 matches A0 only if A01 is the input.)
LEX Program Specification
… definitions …
%%
… rules …
%%
… subroutines …
Input to Lex is divided into three sections with %% dividing the sections. The first %% is always required, as there must always be a rules section. However if we don’t specify any rules then the default action is to match everything and copy it to output. Defaults for input and output are stdin and stdout, respectively. Subroutine part may contain the following functions.
int yywrap()
{
return 1;
}
int main()
{
yylex();
return 0;
}
Regular expression patterns are specified in the rules section. Each regular expresion pattern must begin in column one. This is followed by whitespace (space, tab or newline) and an optional action associated with the pattern. The action may be a single C statement, or multiple C statements, enclosed in braces. Anything not starting in column one is copied verbatim to the generated C file.
Every C program requires a main function. In this case we simply call yylex that is the main entry-point for lex. The lexical analyzer generated by lex is invoked through a call to the function yylex(). yylex is an integer-valued function. The “lexical analyzer” function, `yylex’, recognizes tokens from the input stream and returns them to the parser.
Lex Predefined Variables
yyin
Of the type FILE*. This points to the current file being parsed by the lexer.
yyout
Of the type FILE*. This points to the location where the output of the lexer will be written. By default, both yyin and yyout point to standard input and output.
yytext
The text of the matched pattern is stored in this variable (char*).
yyleng
Gives the length of the matched pattern.
yylineno
Provides current line number information. (May or may not be supported by the lexer.)
Lex Functions
yylex()
The function that starts the analysis. It is automatically generated by Lex.
yywrap()
This function is called when end of file (or input) is encountered. If this function returns 1, the parsing stops. So, this can be used to parse multiple files. Code can be written in the third section, which will allow multiple files to be parsed. The strategy is to make yyin file pointer (see the preceding table) point to a different file until all the files are parsed. At the end, yywrap() can return 1 to indicate end of parsing.
yyless(int n)
This function can be used to push back all but first ‘n’ characters of the read token.
yymore()
This function tells the lexer to append the next token to the current token.
LEX PROGRAMS ..
1) lex program to eliminate single and multiline comments
2) lex program to recognize identifier, keyword and number
3) lex program to find words beginning and ending with a
4) lex program to prepend_line_number_to_each_line
5) lex program to count the number of words
6) lex program to display the line nos containing string hello
7) lex program to find size of a word
8) lex program to eliminate html tags